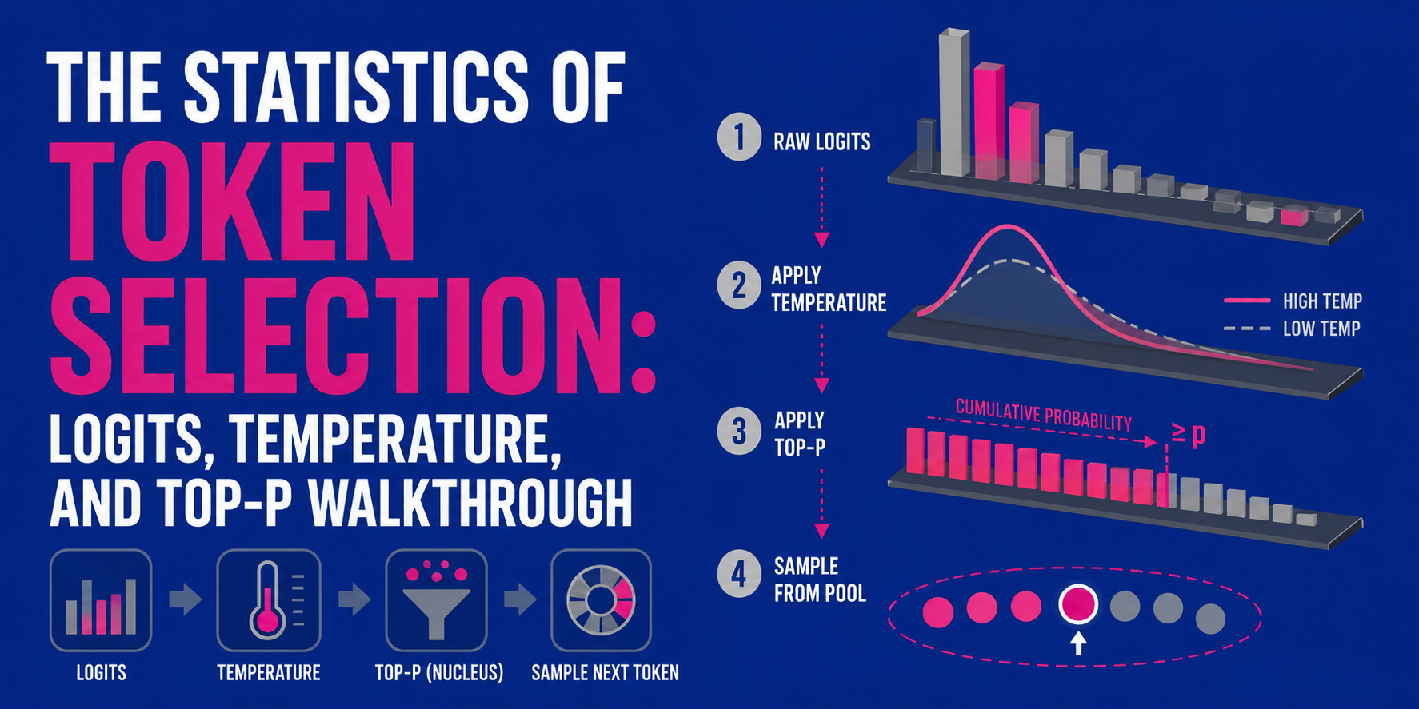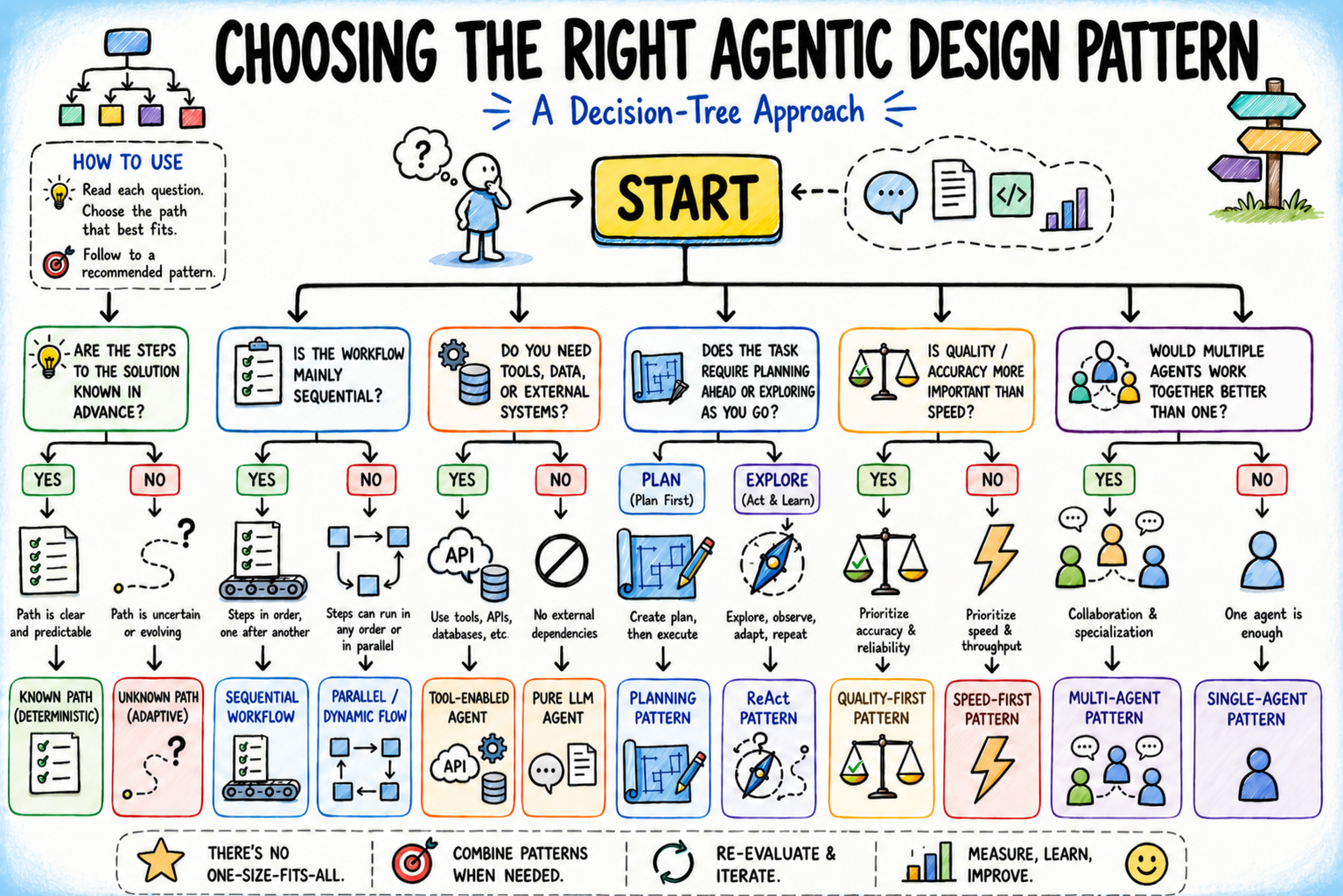
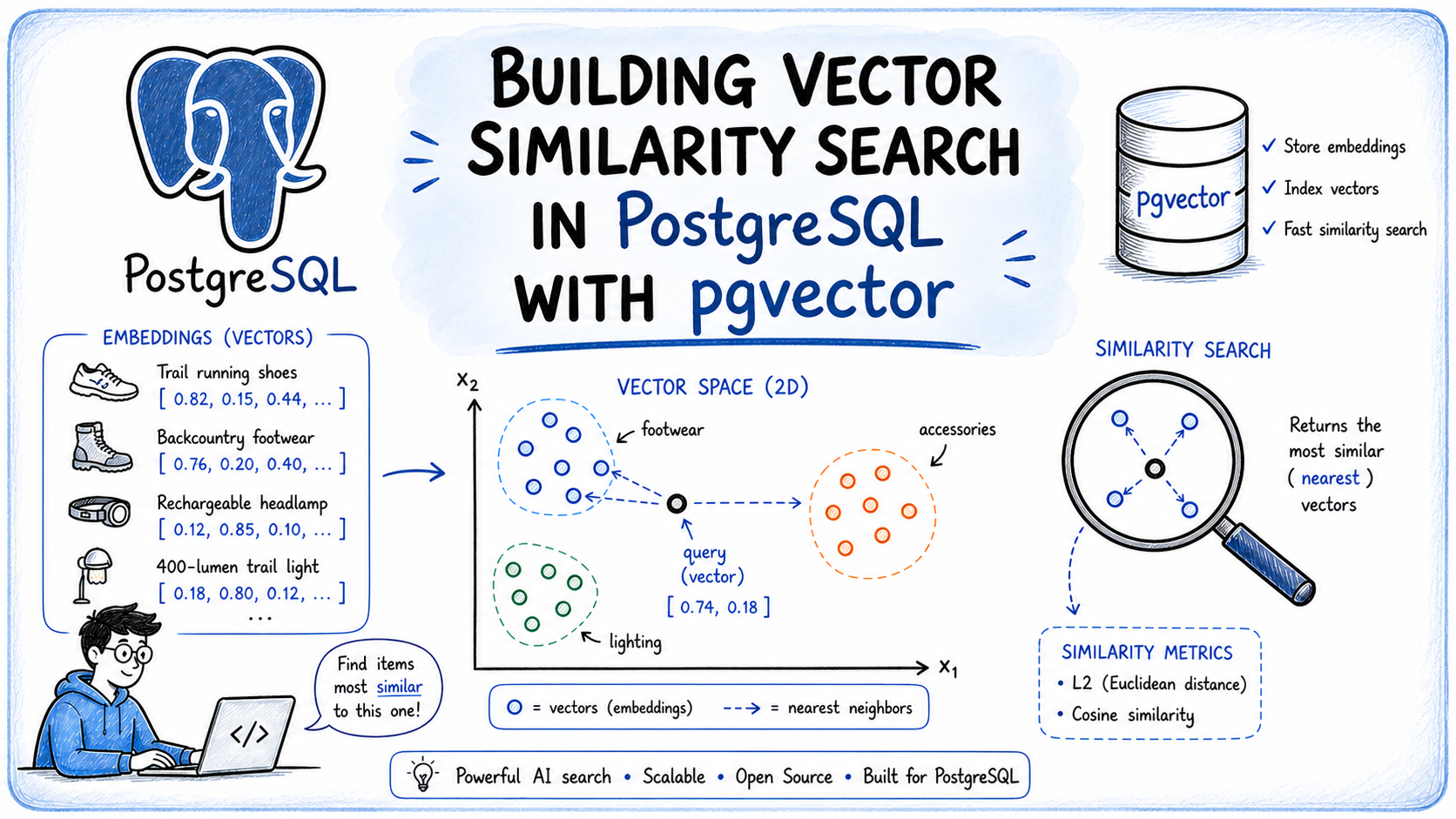
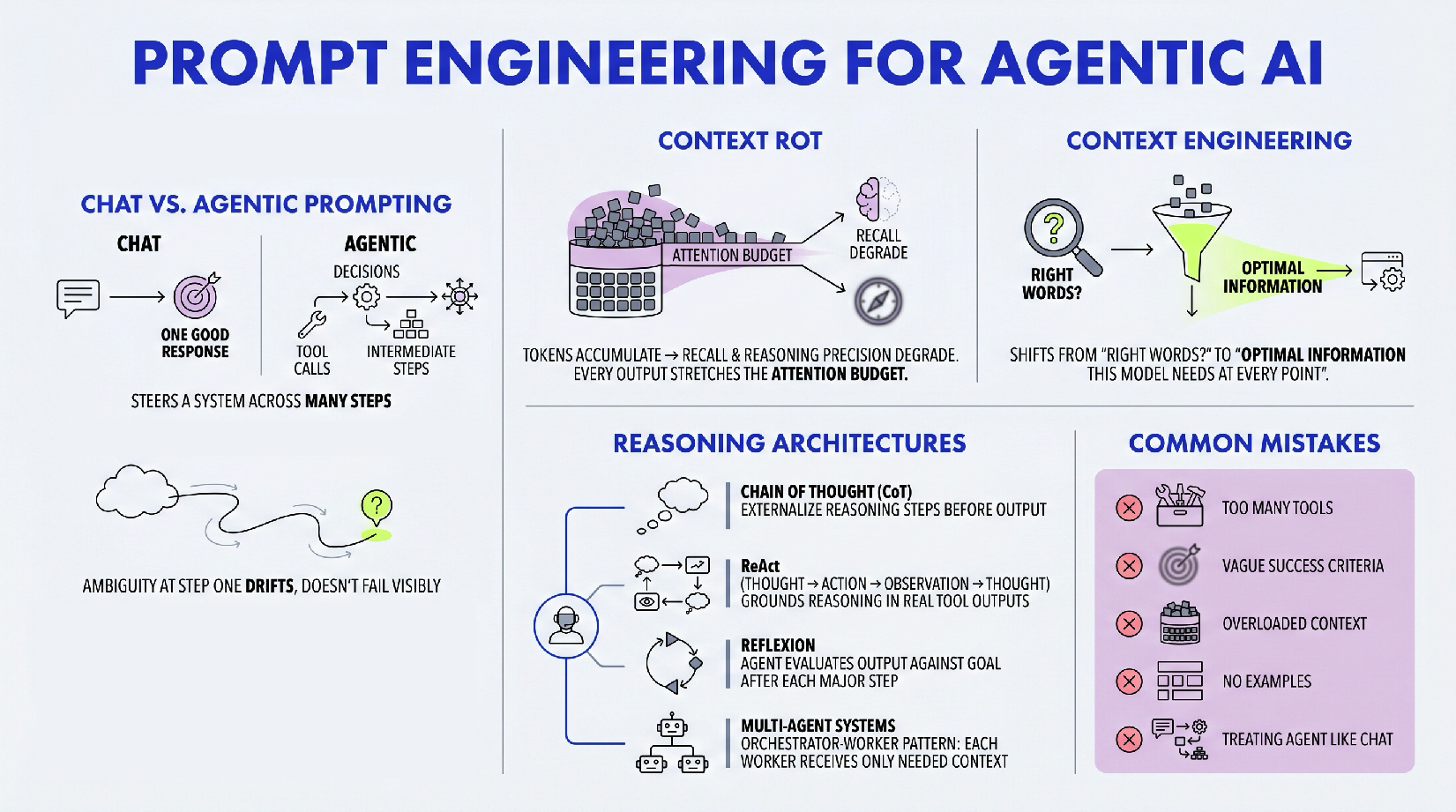





















Essential Chunking Techniques for Building Better LLM Applications

Every large language model (LLM) application that retrieves information faces a simple problem: how do you break down a 50-page document into pieces that a model can actually use? So when you’re building a retrieval-augmented generation (RAG) app, before your vector database retrieves anything and your LLM generates responses, your documents need to be split into chunks.
What's Your Reaction?
 Like
0
Like
0
 Dislike
0
Dislike
0
 Love
0
Love
0
 Funny
0
Funny
0
 Angry
0
Angry
0
 Sad
0
Sad
0
 Wow
0
Wow
0